Guide
Stable Diffusion & ControlNet
Stable Diffusion
Running Stable Diffusion with an API
The Stable Diffusion API makes calls to Stability AI’s DreamStudio endpoint. To use this node, you will need to add your API key which can be found here. If you don’t have a Stability AI account, you will need to create one. You will need to add credits to your account to access the API key.
Generating images with the API will incur a cost. Complete pricing details are outlined here.
With the API node, we support the following configuration parameters:
Engineis the Stable Diffusion model. Odyssey supportsStable Diffusion 3 (1024 x 1024),Stable Diffusion 3 Turbo (1024 x 1024),Version 1.0 XL (1024 x 1024),Version 0.9 XL (1024x1024),Version 2.2.2 XL Beta (512x512), andVersion 1.6 (512 x 512)Stepsare the number of times your image is diffused. The more steps, the longer it will take for the image to generate. We default the number of steps on the API node to 50Seedis the value that Stable Diffusion uses to start your image. Seed values are randomized to start but will stay consistent after your first generation. Clickrandomto randomize a seed value.Guidance scaleis how closely Stable Diffusion follows your promptNumber of imagesis how many images you want to see from your output. If you select more than one, you will need to connect a ‘batch images’ node to Stable Diffusion to display multiple imagesSafe modeturns on Stable Diffusion’s NSFW filterStarting imageinfluence dictates the % of steps that will be devoted to following the connected image input. The more influence the starting image has, the more closely your result will match the imageSchedulerimpacts how the image is generated and defaults to K-DPMPP_2M. Here’s a comparison of all the different schedulers for the same prompt to give a sense of the differences
Running Stable Diffusion locally
Modeloptions are dictated by which models you download when you first start using the app. You can also upload custom models to Odyssey.Stepsare the number of times your image is diffused. The more steps, the longer it will take for the image to generate. If you're using a model that ships with Odyssey, we default the number of steps based on the modelSeedis the value that Stable Diffusion uses to start your image. Seed values are randomized to start but will stay consistent after your first generation. Clickrandomto randomize a seed value.Guidance scaleis how closely Stable Diffusion follows your promptSafe modeturns on Stable Diffusion’s NSFW filter (if available)Schedulerimpacts how the image is generated and defaults based on the selected model.
Compute unitsgive you the option to run Stable Diffusion on your CPU & GPU, CPU & Neural Engine, or all three. We have not found significant performance differences across these three options but there may be some differences when running Stable Diffusion on an older computerReduce memory usageis useful if you’re running Odyssey on an older Mac. While generation time may be slower, reducing memory usage will help ensure that Odyssey does not crash due to using up too much memoryShow Previewswill show the image being diffused out of Gaussian noiseStarting imageinfluence dictates the % of steps that will be devoted to following the connected image input. The more influence the starting image has, the more closely your result will match the image
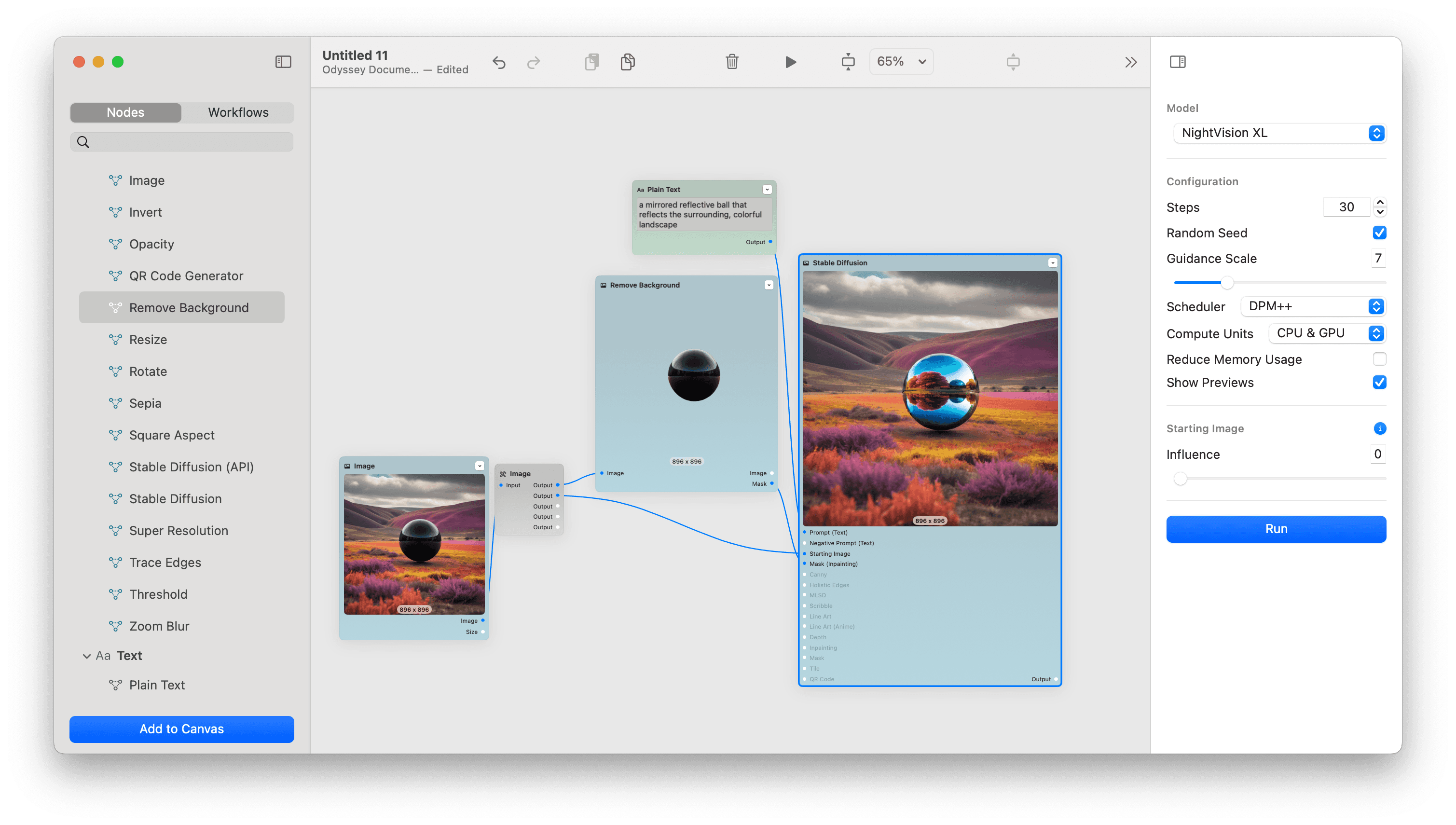
Inpainting
Inpainting can be done through the Mask (Inpainting) input on your Stable Diffusion node. By connecting a mask to the Mask (Inpainting) input, you control which area of an image is manipulated by the model.
To retain a mask, use the Remove Background node then connect the Mask output to the Mask (Inpainting) input.
ControlNet
ControlNet
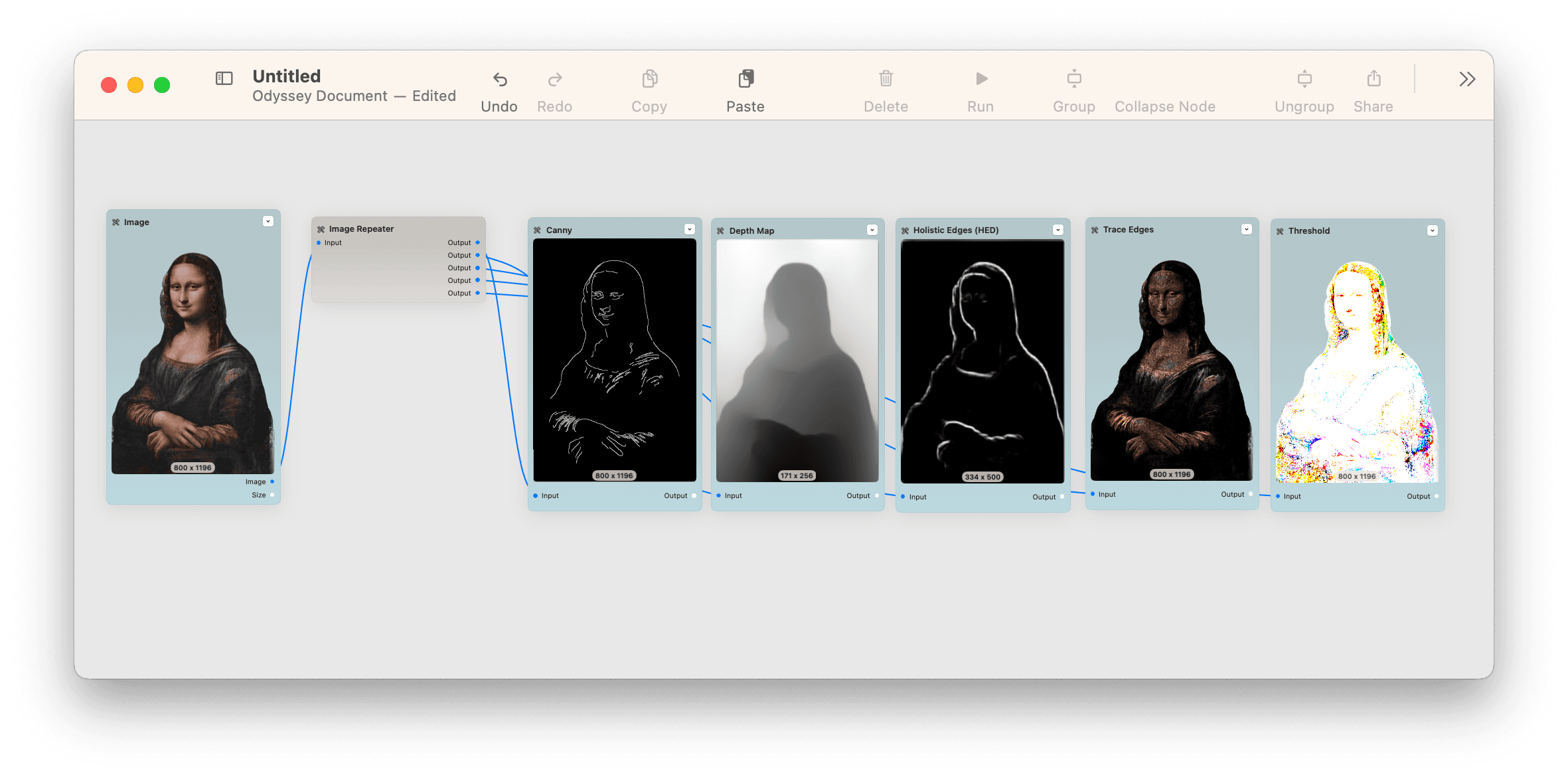
ControlNet is a method of controlling certain regions of an image generated with Stable Diffusion. Odyssey supports a few different methods of leveraging ControlNet through the locally run Stable Diffusion node.
These methods can be found in conditioning. To learn more about ControlNet, read our tutorial here.
The ControlNet options that Odyssey currently supports are:
Canny Edgesuses a Canny edge-detection algorithm to show the edges in an image. You can use the Canny node to control which parts of an image that Stable Diffusion will draw into. Canny works well for objects and structured poses, but it can also outline facial features such as wrinklesHolistic edgesuses holistically nested edge detection to draw edges in an image with softer, less crisp outlines. HED is considered better at preserving details than canny edgesMLSDcorresponds with Odyssey’s “trace edges” node. Trace edges will draw the edges found in an image but, unlike canny or holistic edges, retains the image’s color. You can combine trace edges with a desaturation node to create an image for the MLSD inputScribblecan take a drawing and use the drawing to impact the generated image. This is especially impactful when you use your phone or iPad from a blank image node and draw, for example, a smiley face.Depthuses the depth map node to take a grayscale image that represents the distance of objects in the original image to the camera. Depth is often considered an enhanced version of image-to-image and can help you synthesize subject and background separatelyMaskuses the segmentation from the remove background node to keep the output of Stable Diffusion consistentTileadds detail to an image that lacks detail. To use Tile, take a portion of an image and then run it into the Tile input on Stable Diffusion. The output will fill in a significant amount of detailQR codeuses the QR Monster ControlNet model to engrain QR codes, patterns such as spirals, and text into an image
You can also change the conditioning for ControlNet with the following options:
Conditioning startdictates which step your ControlNet input will begin impacting the imageConditioning enddictates which step your ControlNet input will stop impacting the imageConditioning strengthdetermines how much the ControlNet input impacts the steps it impactsConditioning guidancedetermines how much the image generation adheres to the ControlNet input. Higher guidance means higher adherence to the input
