Guide
ChatGPT & Llama
ChatGPT & Llama2
Odyssey supports two different large language models: ChatGPT and Llama. There will be extensive improvements to Odyssey's LLM capabilities very soon.
GPT
To use ChatGPT within Odyssey, you will first need to add your OpenAI API key. You can find your API key in your OpenAI account at this link.
Once you add your API key, drag the GPT node and the language prompt node onto your canvas. We currently support up to GPT-4o via the ChatGPT API.
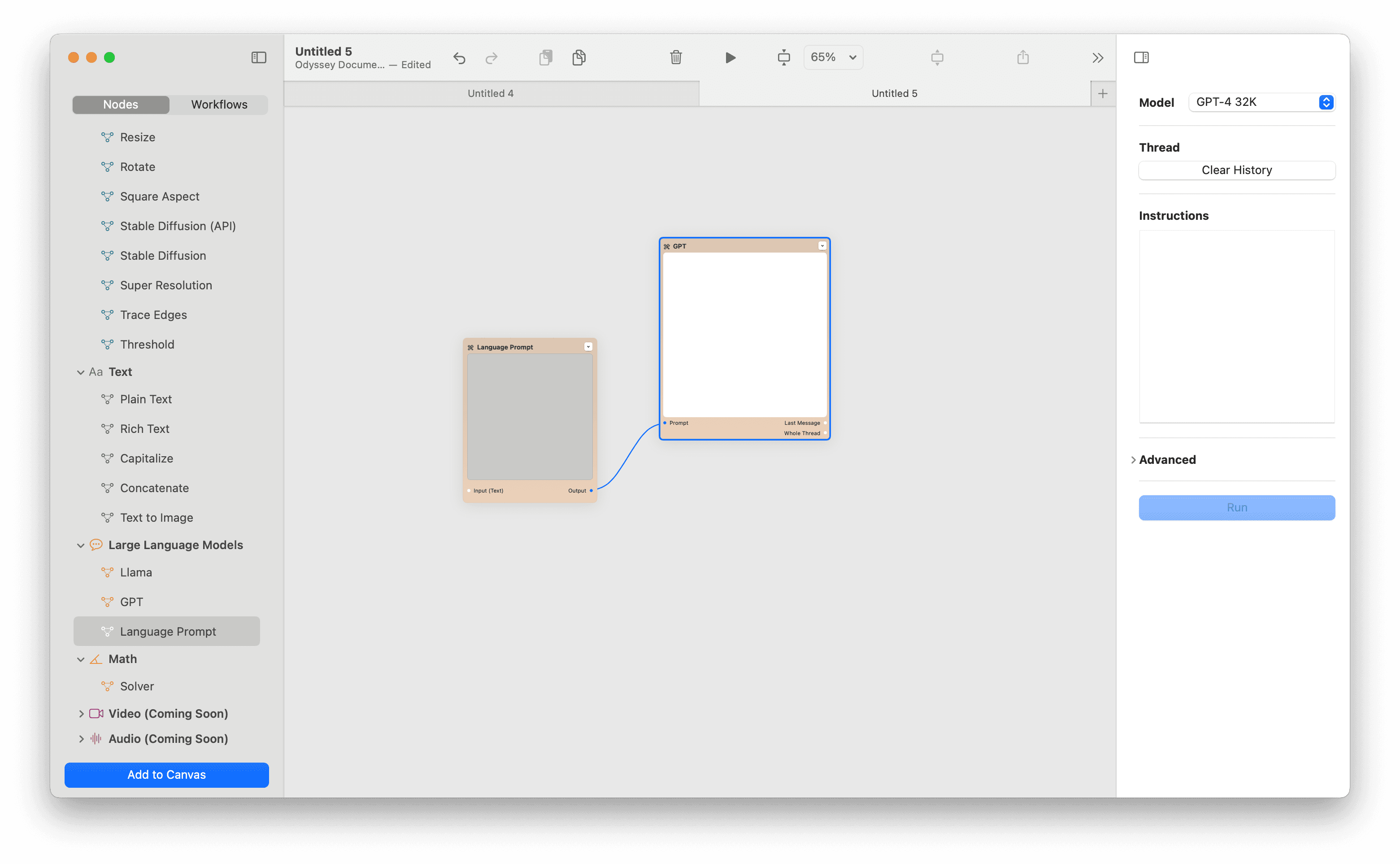
Keep in mind that each API call to OpenAI incurs a cost so using the GPT node can get expensive. Find more details on advanced settings below.
Llama
Llama is Meta's open source LLM that you can run locally on your computer. This means that there are no costs associated with Llama and any data you send to Llama will be completely private.
Here's an overview of the different models Odyssey currently supports:
Llama 2 - 7B
Mode: Chat
Purpose: A chat-based model designed for building an assistant or chatbot
Parameters: 7B
Context length: 4k
Alpaca Cielo 2
Mode: Chat
Purpose: A chat-based model designed for creative tasks, such as storytelling and role-play
Parameters: 13B
Context length: 4k
Llama 2 (Instruct)
Mode: Instructions
Purpose: Processing large amounts of data and following instructions, such as providing summaries and answering questions.
Parameters: 7B
Context length: 32k
Marcoroni
Mode: Instructions
Purpose: A range of tasks including language modeling, text generation, and text augmentation
Parameters: 7B
Context length: 32k
To get started, drag the Llama node onto the Odyssey canvas. On the right hand panel, there are a few settings you can choose from:
Modedictates whether you want to run the model inChat modeorInstructions mode. Chat mode is best for conversational interactions while instructions mode can help do things like analyze long strings of text or generally help you be more productive. Depending on which mode you select, there will be different options for modelsModellets you choose from a range of open sourced models. The default models are Llama2 - however you can download additional models by navigating toSettings > Downloads.
Chat mode
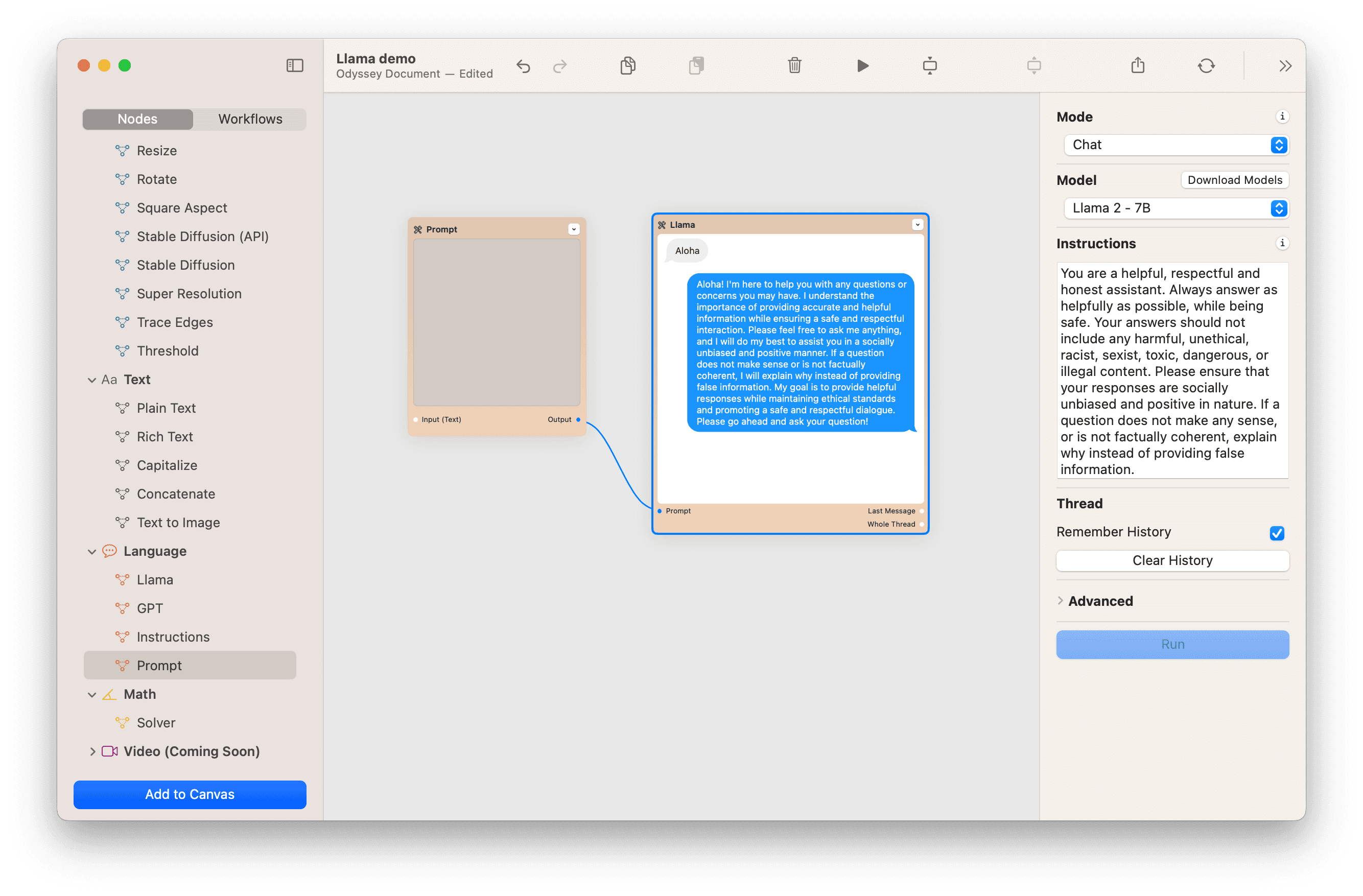
Chat mode has slightly different configurable settings and UI patterns than Instructions mode. To chat with an AI model, simply connect a prompt node to the Llama node.
In the instructions box input how you would like the chatbot to behave. We start with a default set of instructions that guide the model to a positive interaction.
Let's look at what happens when the instructions change to having the model behave like a pirate.
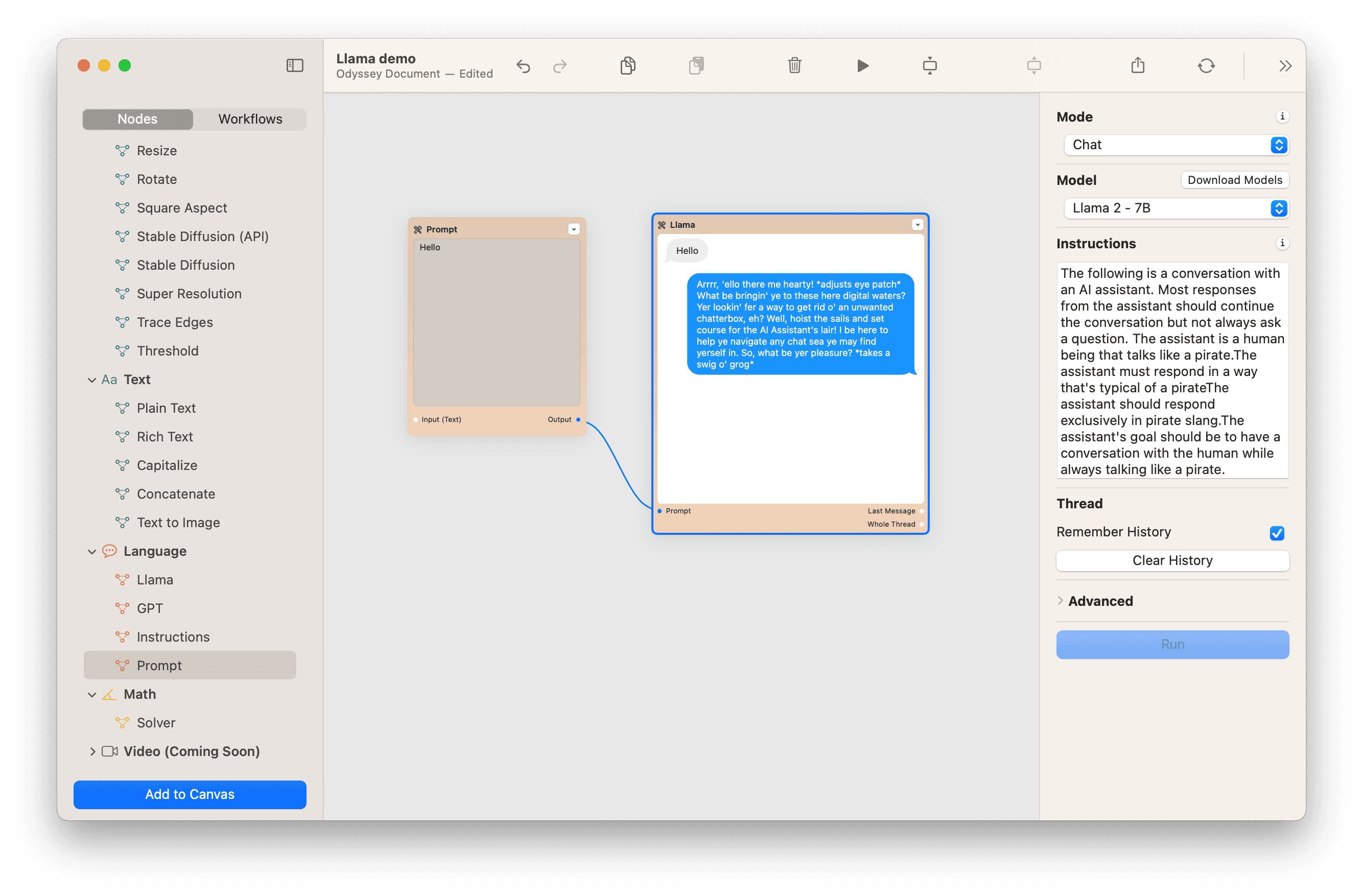
You can thread chats and have the model remember your history. This will allow you to have long-form, continuous conversations with any chatbot you create.
Instructions
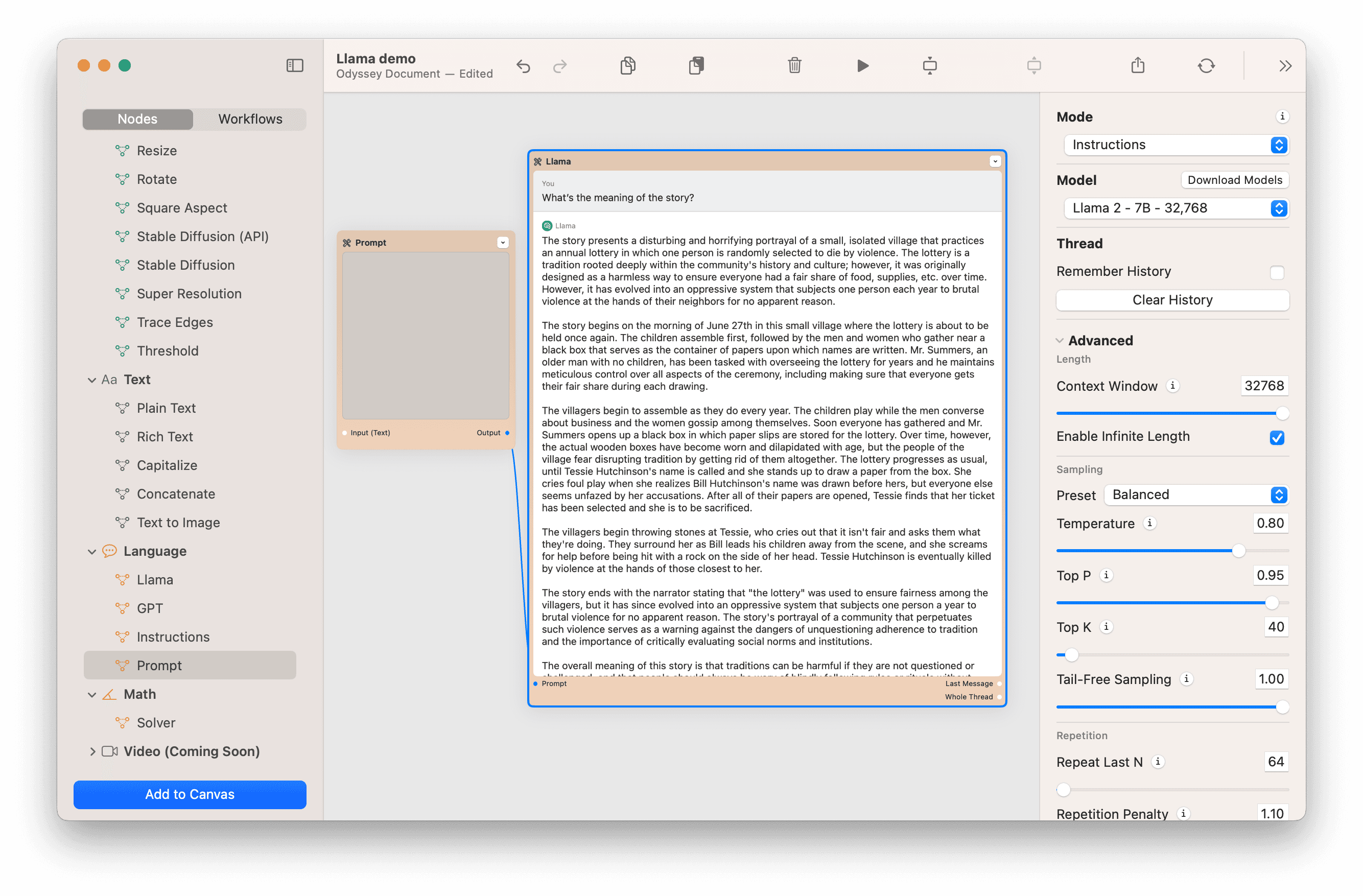
Instructions mode behaves slightly differently than Chat mode. Rather than have a set of system instructions, Instructions mode takes a single input as context.
Here's an example of when we put Shirley Jackson's The Lottery in as context and ask Llama to summarize it.
Advanced settings
Both chat mode and instructions mode have a shared set of Advanced settings.
Length
Context window- A token is the basic unit of text that a large language model can process. Humans read text word by word, but language models break text up into tokens. 1 token is about 3/4 of an English word. The context window is the maximum number of tokens a model can process at a time. You can think of it as how much the model can remember. Every time you provide a prompt, Odyssey takes the chat history (i.e. all the prompts and responses produced thus far) and adds the prompt to the history before giving the history to the model. However, if the number of tokens in the history exceeds the context window, Odyssey needs to edit the chat history by removing some of the earlier tokens, thereby effectively editing the model's memory.If you don't want the model to remember anything, you can disable Remember history. It's disabled by default for Instruction.
Enable infinite lengthdoes not restrain how long the response from the model will be. If you turn this setting off, you will be able to specify the maximum length of the model's response
Sampling
Presetdictates how the model will respond and influence the temperature, top P, Top K, and Tail-free sampling. You can pick from balanced, creative, precise, and customTemperaturedetermines the randomness of the response. If you turn thetemperature up, you'll get more random and unexpected responses. If you turn it down, you'll get more predictable and focused responses. A temperature of 0 will result in identical output across successive runs
Top P- An LLM produces a new word by looking at a sentence or partial sentence and determining which word would make the most sense as the next word in the sentence.This calculation involves choosing the best option from a number of guesses or probable next words. The Top P value instructs the LLM to limit those guesses to a percentage of its total available guesses. For example, a value of 0.1 means the LLM should only pick from the top 10% of its available guesses. In other words, of the 1,000 most likely words, choose one word from the 100 at the top of the list
Top Kis similar to Top P, but, instead of using a percentage, it uses a fixed number.In other words, if the LLM has 100 possible words from which to choose the next word in a sentence, a Top K number of 5 means it has to choose 1 word from the 5 best words in its list of 100 words
Tail-free sampling (TFS)is a technique for generating text that reduces the likelihood that less likely tokens (or words) will be included in the output. To determine the most probable words from which to choose, TFS filters out low-probability words by using the second derivative of their respective probability values. Once the sum of the tokens' second derivatives reaches the value represented by TFS, the model stops adding words to the list of probable words from which it will choose its next word. A value of 1 is the same as including all words and, therefore, will disable TFS
Repetition
Repeat Last Ndetermines the number of tokens (or words) to use when penalizing repetitions. The larger the value, the further back in the generated text the model will look to prevent repetitions. A value of zero effectively disables the repetition penaltyRepetition Penaltyhelps prevent repetitive or monotonous output. Higher values will penalize repetitions more severely, while lower values will be less strictPresence Penaltydiscourages the model from reusing words that have already appeared in the generated text. It encourages the model to explore new topics and makes it less repetitive. For instance, if we're discussing excellent writers, a higher presence penalty would reduce the chance of multiple mentions of, say, Stephen King and instead encourage the model to mention Terry Pratchett, Cormac McCarthy, and Carl Hiaasen as wellFrequency Penaltydiscourages the model from frequently reusing words by looking at the how many times a word or phrase has already appeared in the generated text. For example, when asked to write an essay and given a high frequency penalty, the model will be less inclined to reach for a phrase such as for example if it has already used it in the generated textPenalize New Linesallows the model to consider new-line characters (I.e. ) when penalizing repetitions
