Sep 16, 2024
|
5
min read

When you’re generating AI imagery, there’s a certain randomness that happens. Sure you can control the prompt and the seed value, and new models like Flux are better at following prompts than ever before, but you still can’t always predict what the output is going to be.
Enter ControlNet. Controlnet is a revolutionary method that lets you control specific parts of an image that’s influenced by models like Stable Diffusion.
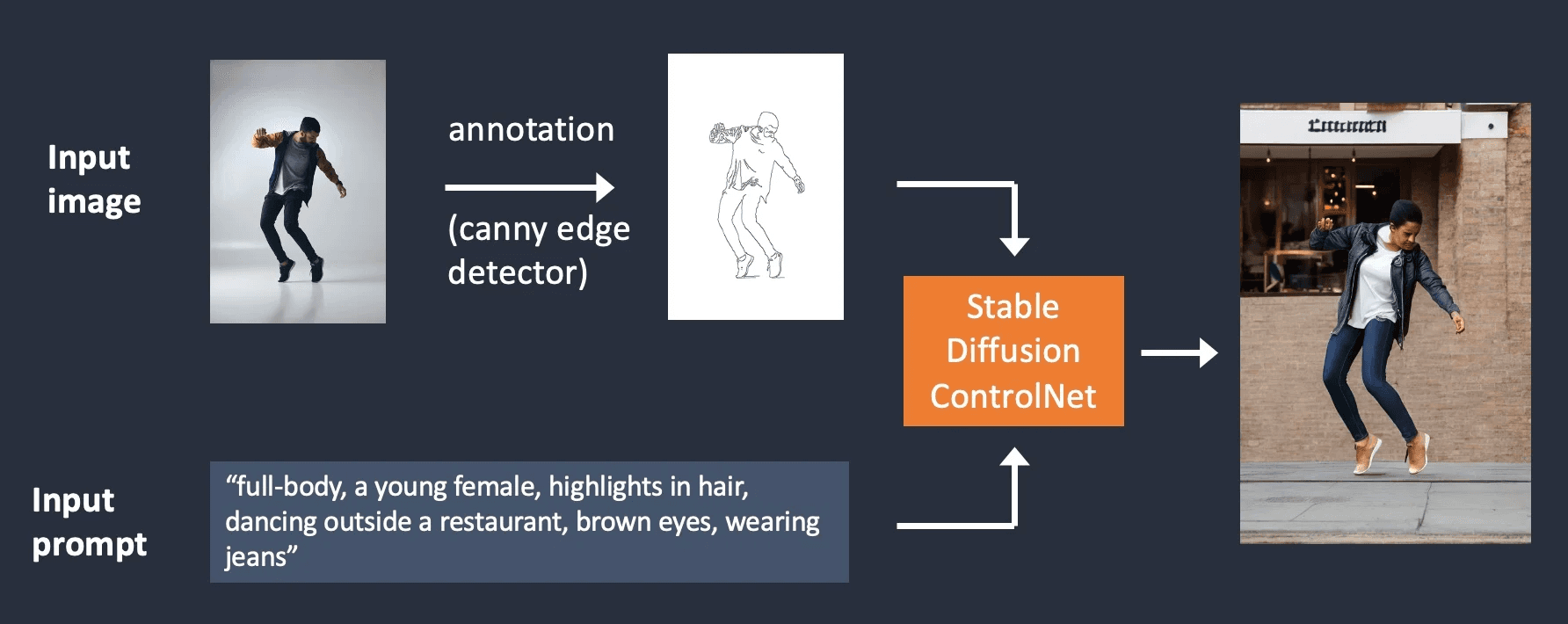
A diagram of how ControlNet works - courtesy of the excellent Stable Diffusion Art
Technically, ControlNet is a neural network structure that allows you to control diffusion models by adding extra conditions. In practice, ControlNet makes it so that instead of generating an image based on a prompt or starting image, you’re able to provide the model with precise inputs, ensuring that the output more closely aligns with your vision.
For instance, imagine feeding your Stable Diffusion model a prompt like "photo of a blue sky with white fluffy clouds." Without ControlNet, the generated image might be a random sky with arbitrarily oriented clouds. But with ControlNet, you can craft a more specific image within those clouds.
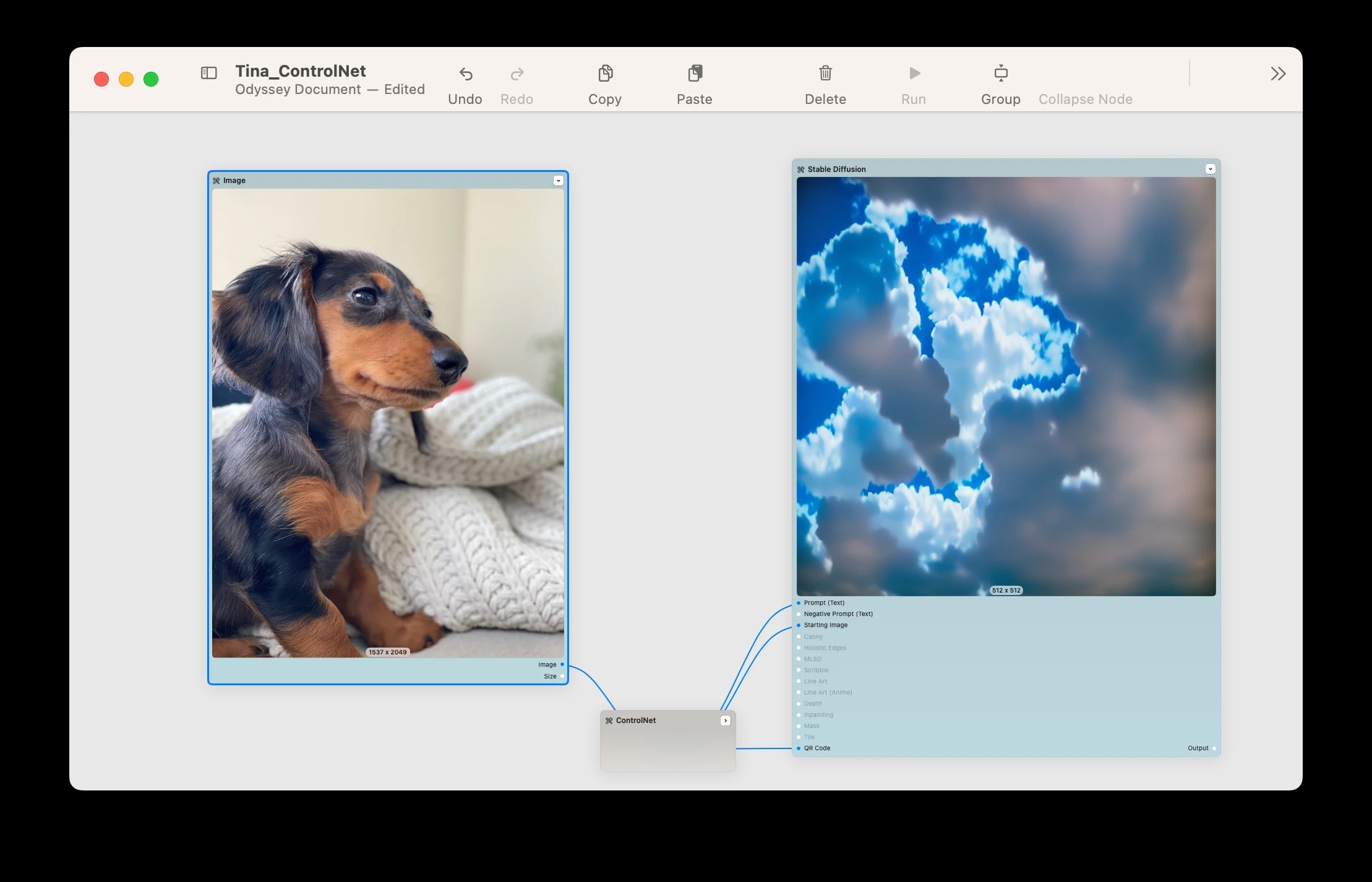
There are ControlNet models for Stable Diffusion 1.5, SDXL, and even some for Flux - though it’s generally accepted that the models around SD1.5 are the most mature and effective. Let’s take a look at some of our favorites.
Canny Edges
This model employs the Canny edge-detection algorithm, highlighting the edges in an image. It's particularly effective for structured objects and poses, even detailing facial features like wrinkles. If you're new to Stable Diffusion, starting with Canny Edges is a great way to familiarize yourself with what ControlNet is capable of.
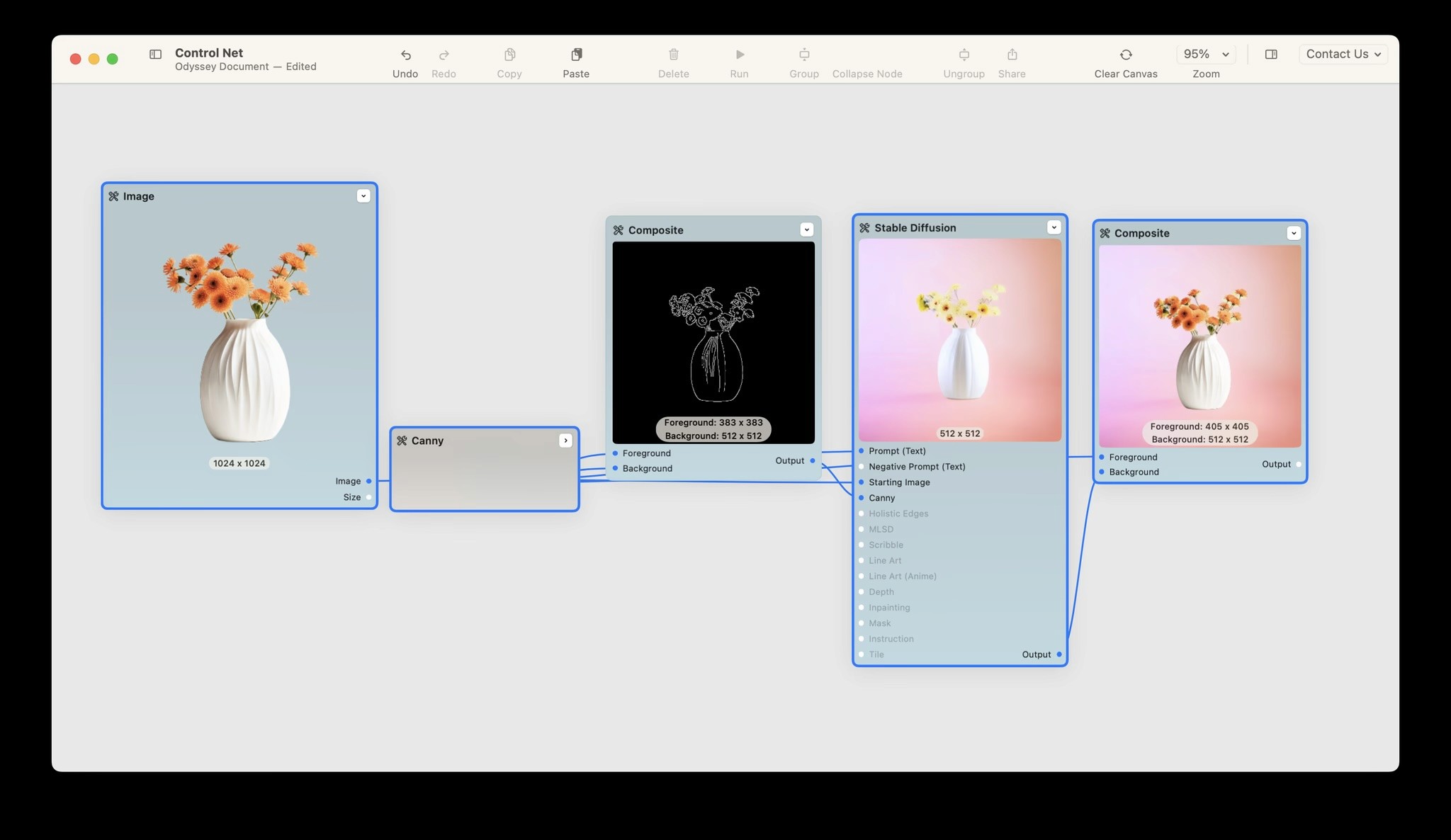
Product photography is a great way to use Canny Edges. In this workflow, we took an image of a vase, ran it through Canny Edges, then generated a new vase with the same shape onto a gradient background. This allowed us to then place the initial vase photograph on top of the generated one - giving us a realistic photography workflow.
Monster QR
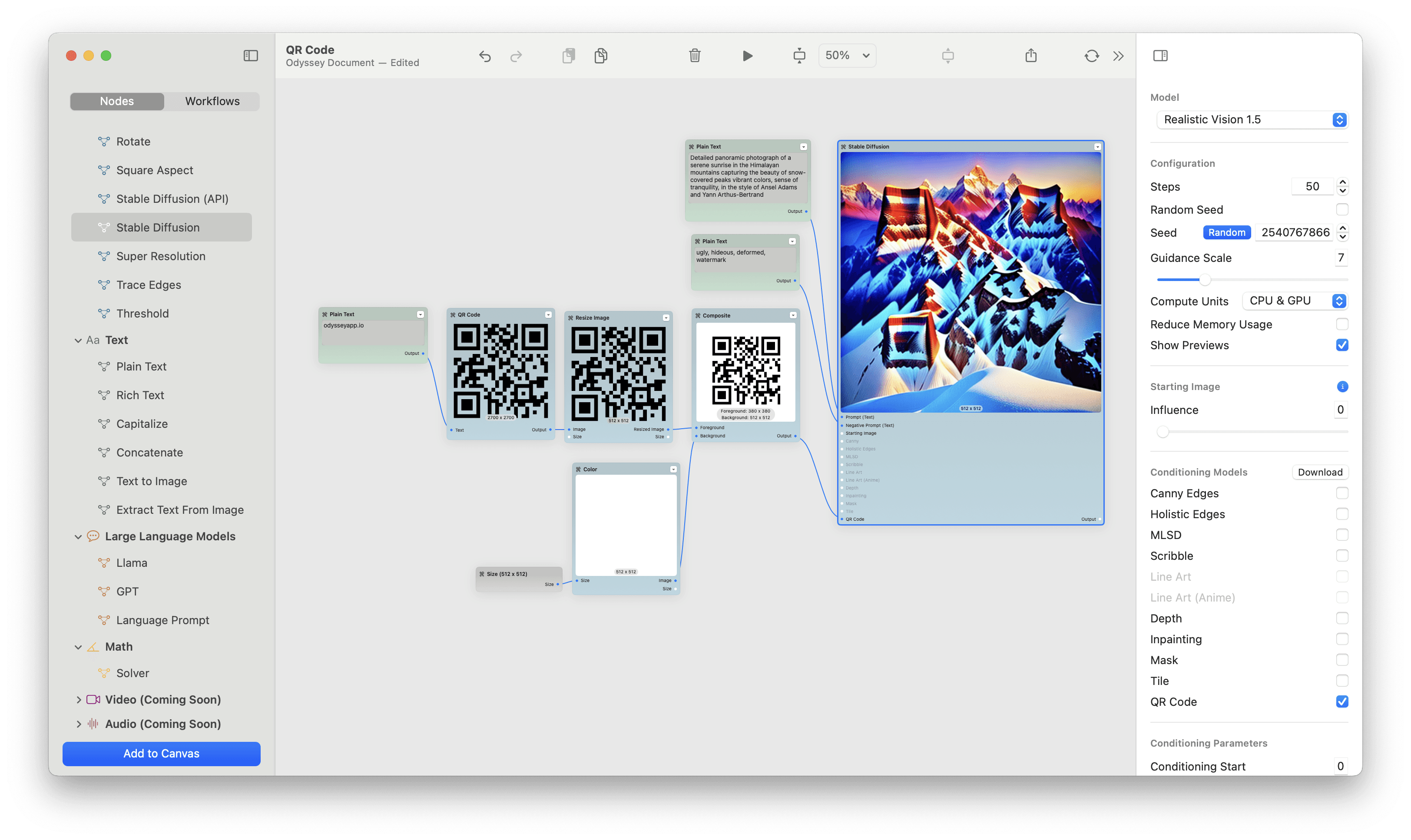
This versatile model embeds QR codes, patterns, and text into images. The QR code model is great at, yes, QR codes - but it's also great at "hiding" figures or words within a generated image.
Monster QR was how the viral Spiral AI art was made. It’s also a great model for hiding words in images or creating artistic, scannable QR codes.
OpenPose
OpenPose allows you to set the pose of any human figure you’re generating by setting the points on a figure - either through UI or via an input image. OpenPose then lets you more granularly control the position a person is generated.
There are also OpenPose models for faces, so you can control a generated image’s facial expression more granularly than you could if you used a prompt.
ControlNet Settings
There are also ways to dictate how much a ControlNet model impacts the final image. Different platforms have different UIs for this level of control - but here’s how we extrapolate it out for Odyssey:
Conditioning Start: This determines the diffusion step at which the ControlNet input initiates. Making ControlNet start later in the image will mean that more of the prompt will come through and the input will be less pronounced.
Conditioning End: This setting decides the diffusion step where the ControlNet input ceases. Like the start point, the end point can dramatically alter the image outcome by making it so the ControlNet input influences the image later in the diffusion process.
Conditioning Strength: This setting influences the ControlNet input's impact on the final image. It's sensitive, so even slight adjustments can produce varied results.
Conditioning Guidance: This determines how closely the generated image follows the ControlNet input. It's akin to prompt guidance, instructing Stable Diffusion on adhering to the input.
You can read more about how to use ControlNet with Odyssey in our complete guide.
